Inhalt
Die Geschwindigkeit von Darktable lässt sich ja bekanntlich durch den Einsatz einer Grafikkarte erheblich erhöhen. Die Frage ist, welche Grafikkarte muss es denn sein? Durch einen Benchmark mit Darktabe lässt sich feststellen, was der Einsatz einer Grafikkarte bringt.
Der Artikel erklärt, was dabei zu beachten ist, wie die gemessenen Zeiten zu interpretieren sind, warum ich einen eigenen Benchmark entwickelt habe (obwohl es schon einige im Netz gibt) und was die Ergebnisse dieses Benchmarks sind.
Ausgangspunkt
Seit 2019 nutze ich für Darktable eine NVIDIA GTX 1050Ti Grafikkarte zur Beschleunigung. Damals zusammen mit einer AMD FX-8350 als CPU. Dabei war der Geschwindigkeitszuwachs gefühlt sehr groß. Mit einer neuen CPU (Ryzen 5 3600) wurde es dann 2020 nochmal in gutes Stück schneller.
Mit den neuen modernen Module von Darktable und durch die Verwendung von Masken war dann aber doch wieder ein Abfall der Geschwindigkeit zu spüren. Nicht in der Art, dass es nervt, aber doch schon merklich. Also wäre mal wieder “Aufrüsten” nicht schlecht. Mittlerweile (02.2023) sind die Preise für Grafikkarten gesunken und es sind auch wieder viele Modelle erhältlich.
Ja, die Auswahl ist groß, aber welches Modell bringt den am meisten oder soviel, dass es merklich schneller wird?
Eine neue Grafikkarte und die Einschränkung der Auswahl
Erster Ansatzpunkt, war sich bei einem Online-Händler das Angebot anzuschauen. NVIDIA Grafikkarten werden bekanntlich besser von Darktable unterstützt, obwohl auch AMD möglich sein soll.
Einschränkung 1: der Preis
Das Modelle für über 2000€ zu haben sind, macht die Entscheidung (für mich) doch ein gutes Stück einfacher. Also habe ich mir ein Limit gesetzt und geschaut, was es für diesen Preis zu kaufen gibt.
Einschränkung 2: die Größe
Das ausgesuchte Modell sah dann doch sehr groß aus. Passt das überhaupt in meinen vorhandenen PC. Also: aufschrauben und nachmessen. Höhe, Breite und zwei Slots – ja, das könnte bei der Länge etwas knapp werden. Glücklicherweise gab es von einem anderen Hersteller ein Modell mit gleichem Chipsatz und Speicher, das aber etwas kürzer war.
Einschränkung 3: das Netzteil
In der Spezifikation war ein Netzteil von min. 650W gefordert. Leider steckten in meinem PC nur 500W. Ein neues Netzteil hätte sowohl den Preis als auch den Einbauaufwand noch oben getrieben. Ok, also dann ein kleineres Modell der Grafikkarte auswählen. Aber auch hier wird ein Netzteil von 550W gefordert. Also noch ein Stufe runter?
Nein, das muss nicht sein. Die Angaben der Hersteller sind mit sehr viel Puffer berechnet. Auf der Webseite von NVIDIA ist dann zu lesen, dass sich die Angabe der Netzteilleistung auf die Kombination mit einer Intel Core i9 10980XE CPU bezieht. Ein Online-Netzteilrechner bringt dann zutage, dass mir bei der Karte mit CPU und den übrigen Komponenten 450W reichen.
Ein weiterer Punkt ist, dass die größeren Grafikkarten eine zusätzliche Stromzufuhr in Form eines 6-8 poligen Kabels benötigen. Hier ist darauf zu achten, dass das Netzteil über ein solches Kabel verfügt.
Ok, dann ist alles geklärt. Aber was ist das???
Einschränkung 4: LHR
Das steht für Low Hash Rate. In den Kommentaren beim Onlinehändler war dann zu lesen, dass es die Karte langsamer macht, wenn sie zum Rechnen (Krypto Mining) verwendet wird. Darktable nutzt die Karte auch zum Rechnen. Also doch lieber AMD?
So wie es aussieht, ist das Ganze nur eine Treiber-Sache. Neuere Treiber sollen die LHR-Funktion nicht mehr nutzen. Also alles gut!
Eine NVIDIA RTX 3060 mit 12GB soll es dann werden.
Die Geschwindigkeit
Jetzt stellt sich die Frage, wie schnell wird denn die neue Karte jetzt sein. Mit welcher Steigerung gegenüber der alten Karte ist denn zu rechnen. Lohnt sich das auch wirklich oder ist man mit einer neuen CPU besser bedient?
Bei einer Suche im Netz zum Thema “OpenCL und Benchmark” stoße ich auf die Seite
https://browser.geekbench.com/opencl-benchmarks
und bekomme die Ergebnisse:
- GeForce RTX 3050 – Score 96416
- Geforce RTX 1050 Ti – Score 19582
Also knapp Faktor 5 – Super !!
Aber dann finde ich noch einige andere Seiten im Netz, die die Leistung von Grafikkarten mit Darktable beschreiben. Leider keine, bei der die RTX 3060 getestet wird. Aber wenn man die Ergebnisse der dort getesteten Grafikkarten mit denen von Geekbench-Browser vergleicht, wird schnell klar, dass der Faktor 5 nicht erreicht werden kann – zumindest nicht mit der RTX 3060.
Die Realität und der Benchmark mit Darktable
Also dann einfach mal selbst messen. Darktable bietet ja die Möglichkeiten dazu und bei den gefundenen Webseiten kann man sich RAW+xmp als Testobjekt herunterladen.
Bei den eigenen Messungen und der Auswertung wird dann klar, dass die Leistungssteigerung sehr modulspezifisch ist. Bei einigen Modulen ist kaum eine Steigerung zu erkennen und bei anderen eine enorme Leistungssteigerung. Problem ist nur, dass bei den heruntergeladenen Benchmark-Testdateien gar nicht alle wichtigen Module verwendet werden. Ja klar, die neuen Module gab es in Darktable zu dem Zeitpunkt, als der Benchmark entwickelt wurde, noch gar nicht.
Ein eigener Benchmark
Also braucht man ein Testobjekt, das die für die Version 4.2.0 typischen Module verwendet. Nicht alle, aber die wichtigsten. Dann stellt sich die Frage, welche RAW-Datei dafür am besten verwendet wird. Dazu habe ich vorab einige Tests ausgeführt, um folgende Fragen zu klären.
Gibt es Unterschiede in den Zeitmessungen bei gleicher Konstellation?
Um das zu klären, wurde die selbe RAW-Datei mehrfach hintereinander mit den gleichen Einstellungen exportiert. Hier waren nur geringe Unterschiede zu erkennen, die zu vernachlässigen sind. Natürlich habe ich darauf geachtet, dass nicht gleichzeitig andere Programme laufen, die Ressourcen verbrauchen. Aber zu 100% lässt sich das nicht vermeiden, wodurch sich die geringen Unterschiede erklären lassen.
Gibt es Unterschiede in den Zeiten bei verschiedenen RAW-Dateien mit gleichen Modulen?
In diesem Test habe ich auf verschiedene Dateien des selben Kameramodells die gleichen Module abgewendet. Die Ergebnisse waren zwar leicht unterschiedlich, aber doch sehr ähnlich sind. Also spielt die Datei selbst keine so große Rolle.
Allerdings sind bei einem anderen Kameramodell schon große Unterschiede zu erkennen. Ja natürlich – das hat ja auch eine andere Auflösung.
Macht es einen Unterschied, ob ein Modul zusammen mit anderen Modulen verwendet wird?
Dazu habe ich die gleiche RAW-Datei mit xmp-Dateien getestet, die zwei verschiedene Sets von Modulen enthalten. Bei den Modulen, die in beiden Sets vorhanden waren, habe ich die Zeiten vergleichen.
Hier waren dann bei einigen wenigen Modulen schon größere Unterschiede festzustellen. So hat beispielsweise das Modul Filmic RGB ca. 0,020 sec gebraucht. Wenn vorher das Modul Sigmoid gelaufen ist (was in der Regel nicht vorkommt, da beide nie in Kombination verwendet werden), dann hat es ca. 0,030 sec gebraucht. Ähnliches war bei dem Modul Vignette zu beobachten. Bei vielen anderen Modulen waren die Zeiten aber auch gleich.
Sind die Einstellungen des Moduls an sich relevant?
Diese Frage ist auch ohne Test leicht mit Jein zu beantworten. Bei einfachen Modulen wird es hier keine Unterschiede geben, weil es zum Beispiel bei der Belichtung egal ist, ob ein Wert mit 0,5EV oder 2EV multipliziert wird. Bei komplizierten Modulen ist klar, dass es Unterschiede geben wird. Wird beispielsweise beim Modul Farbkalibrierung der Weißabgleich ausgeschaltet, dann wird es wesentlich schneller sein, als mit Weißabgleich. Ein anderes Beispiel ist das Modul Diffusion/Schärfe. Hier ist die Laufzeit in starkem Maße von der Anzahl Iterationen abhängig.
Beim Vergleich sollte deshalb mit den gleichen Einstellungen getestet werden, wobei man sich bewusst sein sollte, dass bei der täglichen Verwendung die Zeit anders sein kann, als beim Test, weil andere Einstellungen verwendet werden.
Die Testobjekte
Mit diesen Erkenntnissen habe ich mich für zwei Dateien mit
- 16 Megapixel
- 42 Megapixel
mit jeweils zwei unterschiedlichen Bearbeitungen mit
- typisch anzeigebezogenen Modulen
- typisch szenenbezogenen Modulen
entschieden.
Die Technik des Darktable Benchmarks
Wie OpenCL in Darktable aktiviert und optimiert wird, wird im Handbuch zu Darktable und an zahlreichen Stellen im Netz schon beschrieben. Im einfachsten Fall muss man nur die Grafikkarte in den PC stecken und Darktable starten (Wichtig: vor dem Einbau den PC herunterfahren, ausschalten, aufschrauben und nach dem Einbau wieder einschalten und hochfahren. Hat alles funktioniert, dann wieder zuschrauben.). Genau das habe ich auch gemacht und bei den Messungen auf jegliche Optimierung erst mal verzichtet.
Der erste Benchmark besteht darin, aus den RAW-Dateien ein JPG in voller Größe zu erzeugen. Dazu kann das Programm darktable-cli verwendet werden, um den Export automatisch zu erzeugen, ohne auf der Oberfläche klicken zu müssen.
darktable-cli $raw $xmp $jpg –core -d perf -d tiling –disable-opencl –configdir config > $logfile
Der Parameter -d perf erzeugt Ausgaben mit Zeitmessungen zu den einzelnen Modulen. Die Angabe –disable-opencl sorgt dafür, das OpenCL nicht genutzt wird. Damit erhält man die Zeiten bei reiner Nutzung der CPU, die zum Vergleich genutzt werden.
Der zweite Aufruf
darktable-cli $raw $xmp $jpg –core -d perf -d tiling -d opencl –configdir config > $logfile
Auswertung der Logdatei
Hierzu sollte man verstehen, wie OpenCL in Darktable arbeitet.
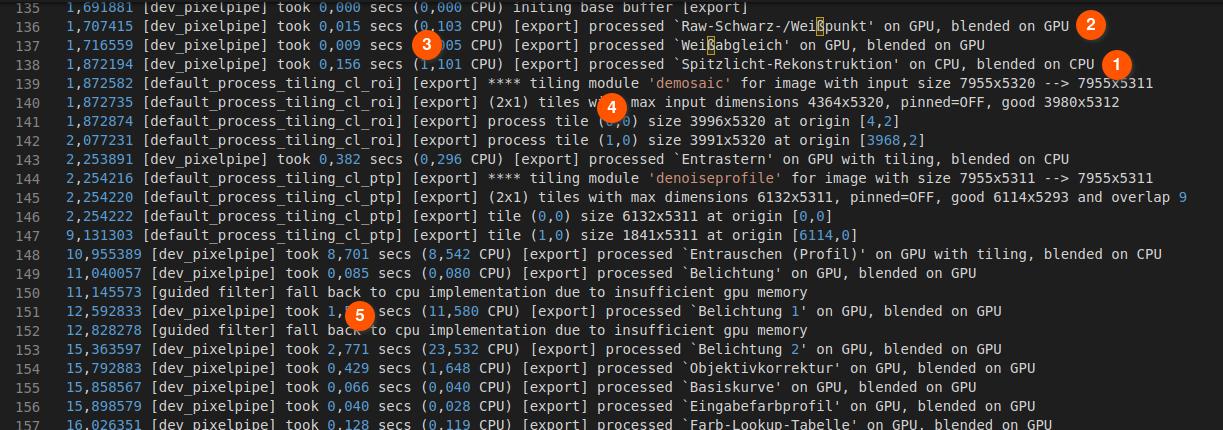
Zunächst einmal ist es so, dass nicht jedes Modul OpenCL unterstützt. Einige Module rechnen immer auf der CPU (Central Processing Unit). Andere verwenden OpenCL und rechnen somit auf der GPU (Grafical Processing Unit). Erkennen kann man das an der Ausgabe “on CPU, blended on CPU” (1) oder “on GPU, blended in GPU” (2). Es gibt auch den Fall “on GPU, blended on CPU”. Dann waren beide an der Berechnung beteiligt. In der Auswertung werte ich das als GPU.
Im vorderen Bereich stehen dann die Zeiten in Sekunden, die ein Modul für die Berechnung benötigt hat (3).
Wenn Darktable erkennt, dass eine Berechnung auf der Grafikkarte nicht möglich ist, weil der Speicher nicht ausreicht, dann gibt es zwei Möglichkeiten. Entweder die Berechnung findet auf der CPU statt, oder es wird ein sogenanntes “tiling” verwendet, was an der Ausgabe im Log zu erkennen ist (4). Hier wird das Bild in mehrere Stücke/Kacheln aufgeteilt (hier 2×1, also 2 Stücke), die dann getrennt nacheinander berechnet werden und wieder zusammengesetzt werden, was natürlich zusätzliche Rechenzeit kostet und somit erklärt, warum das Modul trotz Verwendung der GPU nicht so schnell war.
Das “tiling” kann auch auf der CPU auftreten, wenn der Hauptspeicher knapp ist. Im Gegensatz zur CPU kennt Darktable aber den freien Speicher der GPU nicht und trifft deshalb nur Annahmen aufgrund der Konfiguration. Deshalb kann es vorkommen, dass eine Berechnung auf der GPU gestartet wird, dann aber abgebrochen wird, weil zu wenig Speicher vorhanden ist. Die Berechnung muss dann (nachträglich) auf der CPU ausgeführt werden. Erkennen kann man das an der Ausgabe “fall back to cpu” (5). Dabei kann es sich auch um Teilberechnungen handeln, wie in diesem Fall oben, wo die Maske des Moduls Belichtung berechnet wird. Dieser Fallback erklärt aber, warum das Modul Belichtung trotz Verwendung der GPU etwas langsam war: Die Maske wurde auf der CPU berechnet, das Modul selbst auf der GPU.
Übernahme der Werte in eine Tabelle
Die so ermittelten Zeitwerte trage ich dann für jede Bearbeitung in eine Tabelle (für die vollständigen Ergebnisse siehe Download am Ende des Artikels) ein.
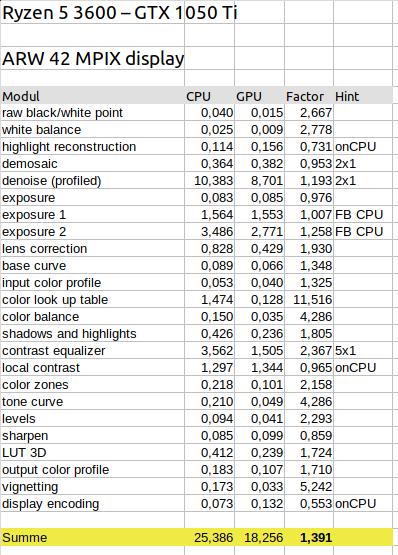
Die Spalte “CPU” beinhaltet die Zeiten des Laufs ohne OpenCL, die Spalte “GPU”, die des Laufs mit OpenCL. In der Spalte “Factor” steht dann der Wert CPU/GPU und zeigt somit, um wie viel das Modul durch Verwendung der GPU schneller ist. Die letzte Spalte mit der Überschrift “Hint” enthält einen der folgenden Hinweise zu den einzelnen Messwerten:
- onCPU – auch bei OpenCL wurde auf der CPU gerechnet
- nxm – es wurde ein tiling verwendet, n und m geben die Aufteilung an
- FB CPU – es hat ein Fallback stattgefunden, die Berechnung wurde abgebrochen und auf der CPU ausgeführt.
Am Ende der Tabelle werden die Werte der einzelnen Module summiert und es wird wieder ein Faktor errechnet. Bei diesem Beispiel ist Darktable mit der GTX 1050Ti ca. 1,4 so schnell, wie bei der reinen Verwendung der CPU Ryzen 5 3600.
Bei den Modulnamen habe ich mich für die englische Version entschieden, da auch der Rest der Ausgabe von -d perf in Englisch ist und so bei Suchen nach einem Modulname diese Ausgaben leichter gefunden werden.
Einige Module habe ich in mehreren Instanzen verwendet. exposure 1 verwendet zusätzlich eine gezeichnet Maske und exposure 2 verwendet eine parametrische Maske. color calibration sorgt für den Weißabgleich, wohingegen color calibration 1 den Kanalmixer nutzt.
Erkenntnisse aus den Ergebnissen
CPU (Ryzen 5 3600) vs GPU (RTX 3060)
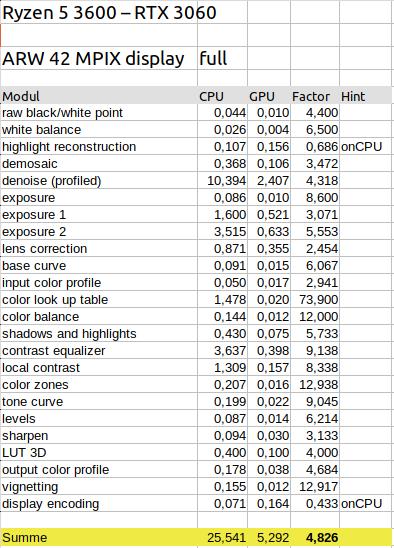
Hier wird mit dem Faktor von ca 4,8 ein gutes Ergebnis erzielt. Der Export ist durch Verwendung der Grafikkarte also wesentlich schneller geworden.
Auffällig ist, dass der Einsatz der Grafikkarte sich bei einigen Modulen wesentlich stärker auswirkt, als bei andern. Hier gibt es eine Spanne von 2,4-facher bis hin zu 74-facher Beschleunigung.
Auffällig ist auch, dass Module, die trotz Aktivierung von OpenCL auf der CPU rechnen (onCPU), langsamer geworden sind.
Ein hoher Faktor bedeutet aber nicht unbedingt, dass sich die Berechnung auf der Grafikkarte für dieses Modul lohnt. Wichtig ist auch, welchen Anteil das Modul am Gesamtergebnis hat. So hat beispielsweise das Modul color zones (Farbbereiche) einen relativ geringen Zeitanteil am Gesamtergebnis. Würde hier keine GPU verwendet, dann würde dieser Anteil trotz des Faktors 13 das Ergebnis kaum verschlechtern. Anders ist es beim Modul denoise (Entrauschen). Hier ist der Zeitanteil am Gesamtergebnis sehr hoch. Somit wirkt sich die Verwendung der GPU trotz des geringen Faktors von 4,3 stark auf das Ergebnis aus. Ein weiterer Beispielfall ist das Modul color lookup table (Farb-Lookup-Tabelle). Der Zeitanteil mit 1,478 ist zwar gesehen am Gesamtergebnis von 25,541 gering. Aber wenn hier nicht die GPU mit Faktor 74 verwendet würde, wären die 1,483 Sekunden bezogen auf die Summe GPU von 5,292 doch relativ hoch und würden das Gesamtergebnis verschlechtern.
Optionen
Aber wie auch immer, als Benutzer von Darktable hat man wenig Einfluss auf diese Werte. Die einzige Entscheidungen, die man treffen kann, sind die,
- eine Grafikkarte zu verwenden oder nicht
- oder vielleicht eine schnellere CPU zu verwenden
- oder bestimmte Module zu verwenden oder eben nicht.
In meinem Fall gibt es wesentlich schnellere CPUs als den Ryzen 5 3600. Aber auch die haben ihren Preis (der den der RTX 3060 übersteigt). Trotzdem wird damit die Geschwindigkeit nicht auf das 4,8fache steigen. Vorteil wäre allerdings, dass von einer schnelleren CPU auch andere Programme profitieren würden.
Das Weglassen von Modulen, macht meiner Ansicht nach bei diesem Workflow nicht ganz soviel Sinn. Entweder man benötigt das Modul oder nicht. Etwas Sinn würde ich bei color balance <-> color zones sehen, aber da die Zeiten hier ähnlich sind, würde ich den Einsatz doch eher anhand der jeweiligen Erfordernisse entscheiden. Ähnlich ist es bei contrast equalizer <-> local contrast. Hier unterscheiden sich die Zeiten zwar stark. Aber obwohl die Module ähnliche Ziele/Aufgaben verfolgen, sind sie in der Bedienung, den Parametern und dem Ergebnis doch sehr unterschiedlich.
anzeigebezogen vs szenenbezogen
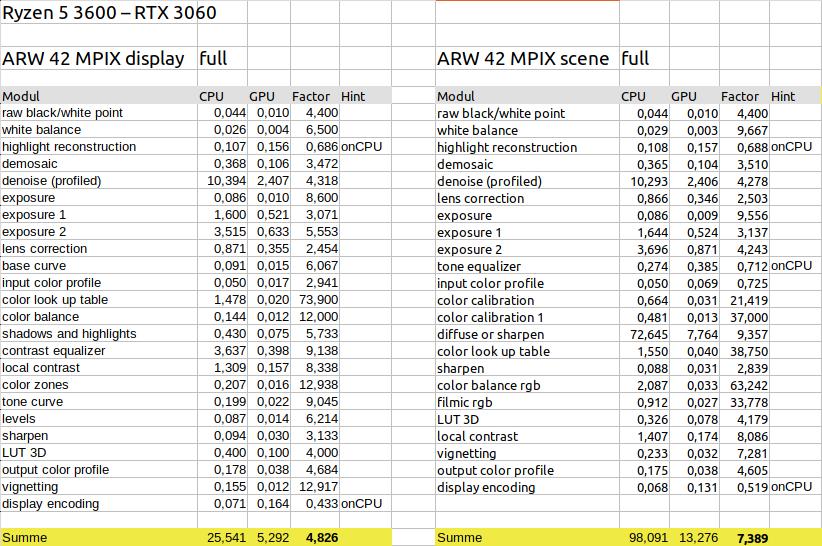
Beim szenenbezogenen Workflow wirkt sich die Verwendung der GPU mit einem Faktor von ca 7,4 noch stärker aus.
Dies liegt ist aber vor allem an der Verwendung des Moduls diffuse or sharpen. Lässt man dieses weg, dann kommt man auch hier auf den Faktor von ca 4,7 – also minimal schlechter als beim anzeigebezogenen Workflow.
Auf der anderen Seite muss man sehen, dass der Einsatz des Moduls diffuse or sharpen zwar den Faktor bezüglich der CPU erhöht, aber auch trotz Verwendung der GPU die Gesamtzeit mehr als verdoppelt. Hier lohnt es sich dann, darüber nachzudenken, statt des Moduls diffuse or sharpen das Modul contrast equalizer zum Schärfen einzusetzen.
Beim Modul tone euqalizer fällt auf, dass dieses immer auf der CPU gerechnet wird, obwohl es sich um ein relativ neues Modul handelt. Hier könnte man sich eine OpenCL Unterstützung wünschen, aber auf der anderen Seite ist der Anteil an der Gesamtzeit doch relativ gering.
42 Megapixel vs 16 Megapixel
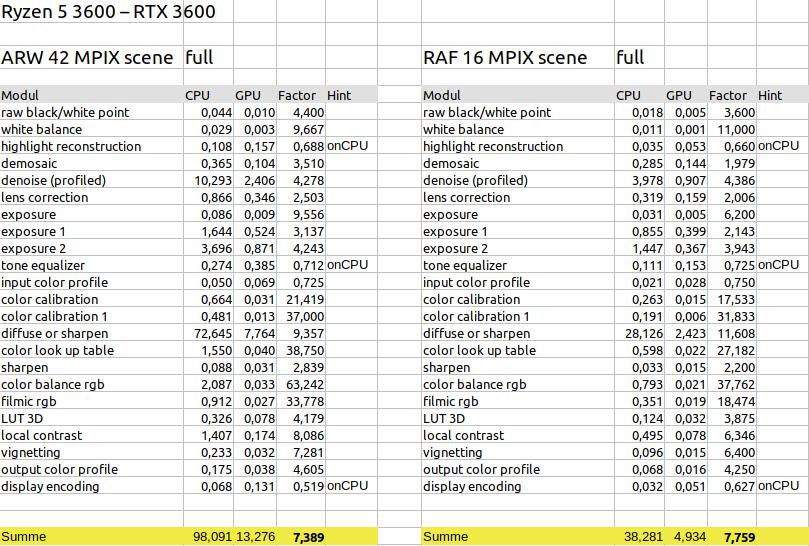
Was den Beschleunigungsfaktor angeht, sind hier nur minimale Unterschiede zu erkennen. Das ändert sich etwas, wenn das Modul diffuse or sharpen weggelassen wird (4,7 / 4,1), aber doch nicht sehr stark. Auch die Faktoren der einzelnen Module liegen bis auf einige Ausnahmen (raw black/white point, color look up table, color balance rgb, filmic rgb) in ähnlichen Bereichen.
Allerdings unterscheidet sich die Gesamtzeit deutlich, was aufgrund der unterschiedlichen Auflösung zu erwarten war. Das Verhältnis der Zeiten passt zu dem Verhältnis der Auflösung (42/16 = 2,625; 98/38 = 2,579; 13/5 = 2,600). Somit könnte man es hier wagen, auch auf andere Auflösungen zu schließen. So sollten beispielsweise bei 24 Megapixel die Zeiten um den Faktor 1,750 (=42/24) geringer sein, als bei 42 Megapixel. Aber: diese Annahme gilt nur für den Export der Datei in voller Größe und nicht für die Arbeit in der Dunkelkammer von Darktable.
Auch zu beachten ist, dass es sich hier um zwei unterschiedliche Arten von Sensoren handelt – einmal Bayer und einmal X-Trans. Dies macht sich auch in den Zeiten des Moduls demosaic bemerkbar. Hier müssen die Zeiten der 16 Megapixel wesentlich geringer sein. Bei Verwendung der GPU sind sie aber sogar höher. Dies liegt zum einen an der Art des Sensors selbst, aber auch an dem Verfahren, das Darktable zum Entrastern verwendet. Hier könnte man jetzt experimentieren und ein anderes Verfahren auswählen (was ja in Darktable möglich ist). Aber da das Modul nur einen geringen Anteil an der Gesamtzeit hat, lohnt sich dieser Aufwand nicht.
Grafikkartenvergleich RTX 3060 vs GTX 1080Ti
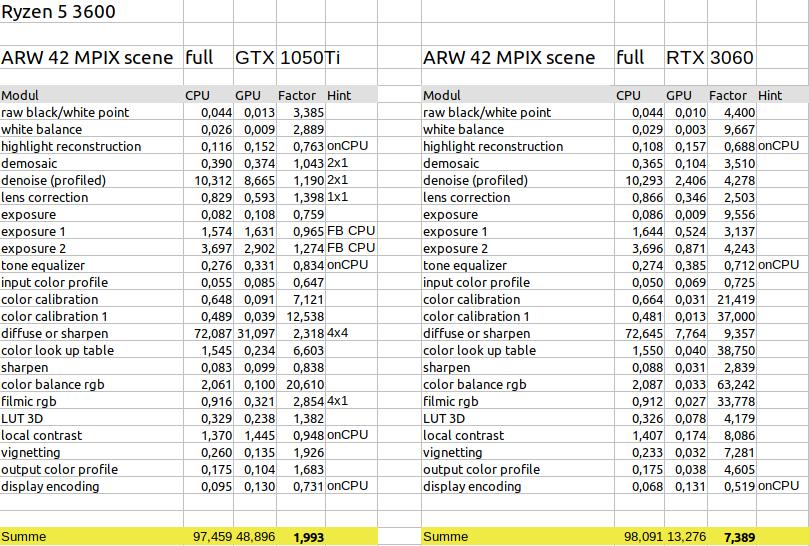
Zum Schluss dieses Benchmarks der Vergleich der beiden Grafikkarten – alte gegen neue. Hat sich das Upgrade gelohnt?
Die Zeiten für die reine Verwendung der CPU sind in beiden Fällen gleich, was zu erwarten war. Die Zeit beim Einsatz der GPU hat sich mit der neuen Grafikkarte rapide verbessert. Hier ergibt sich ein Faktor von ca 7,4 (gegenüber der CPU) statt ca. 2.
Damit ist die neue Grafikkarte um den Faktor 3,7 schneller als die alte.
Das ist zwar nicht das Ergebnis, was aufgrund des Performace-Charts aus dem Netz zu erwarten war (das 5 fache), aber immer noch ein sehr gutes Ergebnis. Und es war ja schon von vornherein klar, dass der Faktor 5 nicht erreicht wird.
Im displaybezogenen Workflow oder bei Verzicht auf das Modul diffuse or sharpen sinkt der Faktor neue Grafikkarte/alte Grafikkarte auf den Faktor 3,5. Bei der Verwendung der 16 Megapixeldatei liegt er bei nur noch ca 3,0.
Vergleicht man die einzelnen Module, dann ist zu erkennen, dass ein Faktor von 5 schon möglich ist, wie im Falle des Moduls color lookup table. Bei dem Modul filmic rgb wird sogar ein Faktor von fast 12 erreicht. Dies ist aber nicht der Geschwindigkeit der neuen Karte zuzurechnen, sondern dem Arbeitsspeicher. Bei der alten Karte musste das 42 Megapixel große Bild in 4 Kacheln (Hint 4×1) zerlegt werden, damit der Speicher zur Berechnung reicht. Ähnlich ist es beim Faktor 8 der beim Modul local contrast entsteht. Hier hat Darktable aufgrund des Speichers entschieden, das Modul auf der CPU statt der GPU zu berechnen (Hint FB CPU).
Zweiter Benchmark
Die Hauptarbeit mit Darktable besteht jedoch nicht darin, Dateien nach jpg zu exportieren, sondern Bilder in der Dunkelkammer zu bearbeiten. Obwohl das Exportieren ein guter Maßstab für die zusätzliche Performance einer zusätzlichen Grafikkarte ist, ist das doch etwas anderes.
Deshalb besteht der zweite Benchmark darin, Darktable mit GUI zu starten und alle Bilder nacheinander in die Dunkelkammer zu laden, um zu sehen, welche Zeiten die einzelnen Module benötigen, um das Bild zu verändern. Das wurde jeweils mit und ohne OpenCL gemacht, um vergleichen zu können, was der Einsatz der Grafikkarte bringt.
Export vs Dunkelkammer
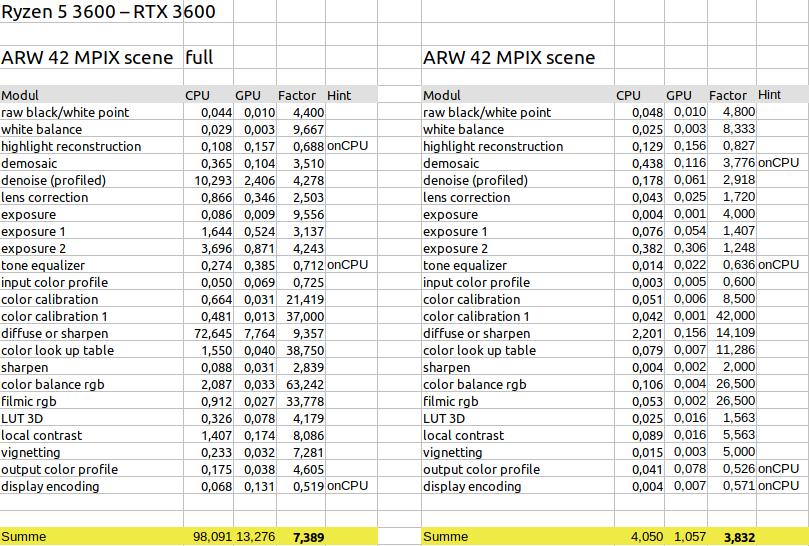
Hier fällt auf, dass die Zeiten wesentlich geringer sind, als bei einem Export. Das war aber auch zu erwarten, da die Auflösung des Bildbereichs in der Dunkelkammer wesentlich geringer ist. In Versuchen habe ich herausgefunden, dass ein Export in der Größe des Bildschirmbereichs der Dunkelkammer ähnliche Zeiten liefert, die aber doch immer etwas länger waren. Beim Bearbeiten in der Dunkelkammer scheint doch noch mehr auf Performance optimiert zu werden. Das hier optimiert wird, erkennt man auch daran, wenn Werte in Modulen geändert werden, die weiter oben in der Bearbeitungskette (Pixelpipe) liegen. In diesem Fall sind oft (aber nicht immer) keine Ausgaben mit Messwerten zu den weiter unten liegenden Modulen vorhanden. Das bedeutet, dass diese Module nicht ausgeführt werden und die Verarbeitung der Pixelpipe mittendrin auf einem im Cache gespeicherten Bild beginnt.
Neben den kürzeren Zeiten für die Bearbeitung in der Dunkelkammer ist aber auch der Faktor für die Grafikkarte von ca 7,4 auf 3,8 gesunken. Somit lohnt sich der Einsatz einer Grafikkarte für die Bearbeitung in der Dunkelkammer immer noch, aber die Auswirkungen sind längst nicht so stark wie beim Exportieren von Dateien.
Auch im anzeigebezogenen Workflow und bei der Verwendung der 16Megapixel Datei zeigt sich eine Halbierung des Faktor im Gegensatz zu Export (Die entsprechenden Daten können im Excel eingesehen werden – siehe Download unten). Lässt man beim szenenbezogenen Workflow das Modul diffuse or sharpen weg, dann bleibt auch hier ein Faktor von ca 2 übrig.
Alternative neue CPU?
Unter diesem Gesichtspunkt wäre die Aufrüstung durch eine CPU mit doppelter Leistung besser gewesen, da auch andere Programme davon profitieren. Der Perfomance-Schub durch die GPU einer Grafikkarte scheint sich vor allem bei größeren Auflösungen bemerkbar zu machen. Bei kleineren Auflösungen scheint der Vorteil durch die Verwaltung, die dann auf der CPU stattfindet, aufgefressen zu werden. Das ist auch der Grund, warum die Performance beim tiling (dem Aufteilen des Bildes in mehrere Kacheln) abnimmt.
42 Megapixel vs 16 Megapixel
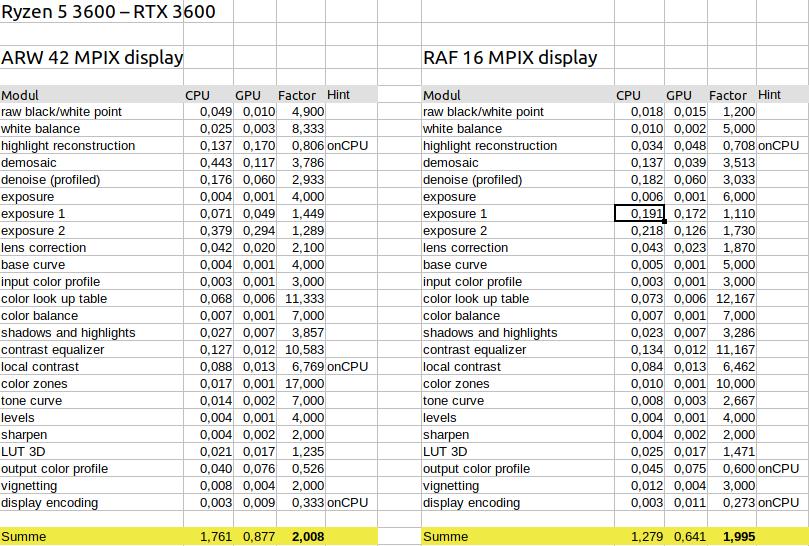
Hier fällt auf, dass die Zeiten für die 42 Megapixel und für die 16 Megapixel sowohl im Falle CPU als auch im Falle GPU sich zwar unterscheiden, aber nicht so stark, wie man es aufgrund der Auflösungen vermuten würde. Beim Export wurde hier ein Faktor von ca 2,6 festgestellt. Bei der Bearbeitung in der Dunkelkammer beträgt der Faktor nur noch knapp 1,4 (1,761/1,279). Betrachtet man die einzelnen Zeiten der Module, dann ist hier nur in den Modulen oberhalb von demosaic ein großer Unterschied festzustellen. Bis zu diesem Modul wird wohl mit der vollen Auflösung gearbeitet, danach nur noch mit der Auflösung des Bildbereichs der Dunkelkammer. (Wodurch der Unterschied bei den exposure Modulen zustande kommt ist mir nicht klar. Er ist in der szenenbezogenen Variante genauso vorhanden.)
Wer also überlegt, sich eine Kamera mit höherer Auflösung zu zulegen, kann sich freuen. Denn die Performance wird bei der Bearbeitung nicht in gleichem Maße sinken, wie die Auflösung steigt. Wenn beim Export dann ebenfalls nicht die volle Auflösung verwendet wird, dann fallen die Performanceeinbußen insgesamt eher gering aus. Natürlich kann man sich dann fragen, was die hohe Auflösung überhaupt bringt. Für manche Fälle machen die vielen Pixel dann eben doch Sinn und – für mich der wichtigste Aspekt – es besteht die Möglichkeit Ausschnitte zu machen, ohne dass die Auflösung in den kritischen Bereich kommt.
Grafikkartenvergleich RTX 3060 vs GTX 1080Ti
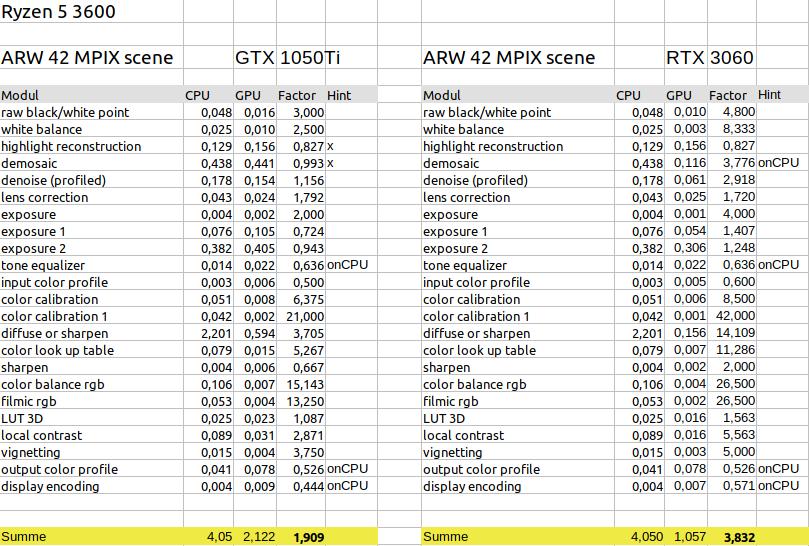
Auch beim Vergleich der Grafikkarten macht sich der schlechtere Faktor im Gegensatz zum Export bemerkbar. Statt des Faktors 3,7 für neue Karte/alte Karte wird nur noch ein Faktor von ca 2,0 erreicht. Dieser sinkt wie auch im Falle des Exports mit der Verwendung des szenenbezogenen Workflows oder dem Wegfall des Moduls diffuse or sharpen. Und er fällt weiter bis auf ca 1,7 wenn statt der 42 Megapixel nur 16 verwendet werden.
Den Benchmark selbst ausführen
Wer möchte, der kann den Benchmark auch für die eigene Hardware ausführen. Die Dateien und Scripte zum Starten des Benchmarks können hier heruntergeladen werden.
Er funktioniert mit Darktable 4.2.0 und auch mit Darktable 4.2.1 unter Linux und Windows. Wer Darktable selbst kompiliert, der sollte darauf achten, dass die Compiler-Optimierungen eingeschaltet sind (–build-type Release – Man sollte es nicht glauben, aber bei diffuse or sharpen bringt das den Faktor 1,5 auf der CPU).
In dem Paket ist auch die OpenOffice-Datei mit meinen Ergebnissen enthalten. Dieses Dokument beinhaltet auch eine kleine Anleitung. Wer seine Ergebnisse gerne teilen möchte, der kann mir die Logdateien des Benchmarks senden (info@foto.zenz-home.de). Ich nehme sie in die OpenOffice-Datei auf und aktualisiere den Download.
Weitere Benchmarks
… auf anderen Webseiten habe ich hier gefunden: